
Cloud saving plans alone won’t minimise all your avoidable cloud costs. Here is why…
An optimist, a pessimist, and a FinOps pro walk into a bar.
The bartender pours them each half a pint in a pint glass.
The optimist smiles and says, “Perfect, a half full glass! This is going to be a great night. Opportunities abound. Life is good.”
The pessimist sighs and says, “It’s half empty. This will be gone before I know it, and then I’ll have to spend more money. And tomorrow? Terrible headache. Dry mouth. Regret. It’s never worth it.”
The FinOps pro doesn’t even pick up the glass, and says, “Why are we paying for a pint glass when a half-pint glass would do the job? And why are we buying rounds individually, have you looked at the bulk discount on a pitcher? If we’d reserved a table in advance, we’d have gotten the happy hour rate. And …

Unlike common perception, the cloud is not usually priced as pay per use. Cloud mostly is priced as pay what you provision, even if you do not run any applications on the hardware provisioned. Wasted cloud spend of nearly 30% across the industry is the result of overprovisioning on the cloud. This may also include overprovisioned reservations and committed usage. The latter typically forces customers to pay for the agreed discounted provisioning or utilisation, which may lead to overprovisioning and inefficient utilisation.
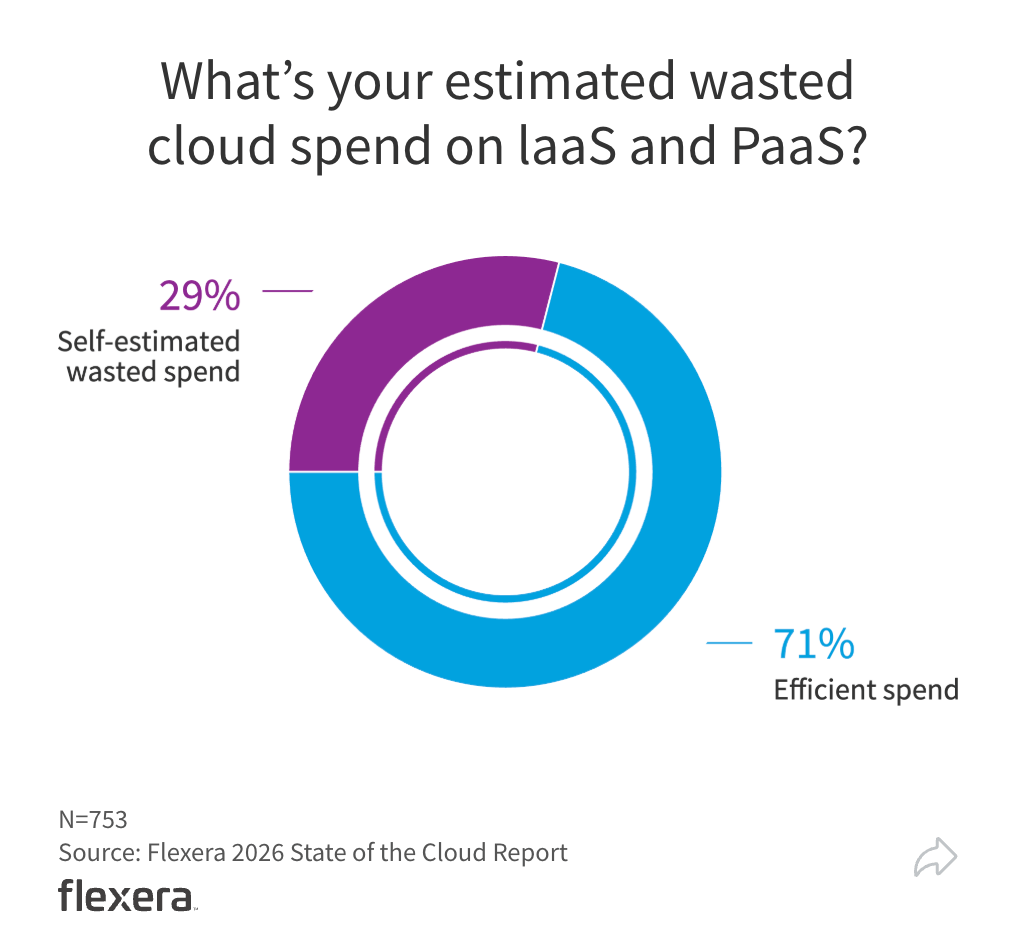
This is analogous to a glass a little over two thirds full. The optimists in an enterprise will say that we have additional capacity to scale for growth. For the pessimists, this won’t be enough. They would wonder what if there are spikes that stretch beyond the excess 30% capacity.
And the FinOps folks will wonder why even have this excess capacity when the cloud can scale elastically? Why can our systems not scale out when the load increases and scale back in when the load reduces?
Well, there are business and technical causes why firms end up with such high levels of overprovisioning.
Business causes leading to overprovisioning
Usually overprovisioning occurs because firms continue to use traditional on-prem procurement and budgeting processes for public cloud. This typically requires collecting upfront compute, storage and network needs for the whole year. These are costed and the required resources provisioned, in a good scenario, close to when they are needed.
Cloud consumers within the firms add buffers to avoid the risk of running out of capacity mid year. They may also give provisioning timelines much earlier than necessary. Worse, they may continue to hold on to resources no longer needed in situations where business volumes on certain systems have declined.
This exercise, which is usually conducted with the intent to forecast costs, ends up also forecasting waste, pretty much consistently. This is the extra cost to the business that it could avoid.
Technical causes leading to overprovisioning
Much of the enterprise technology is tightly coupled and monolithic. Teams may find it easier to scale monolithic services vertically but there are limits to capacity utilisation when vertically scaling services. This means that beyond a certain load increase, increasing capacity for vertical scaling does not have the corresponding effect of better or sustained performance. Unless teams have tested for such thresholds, they may overprovision without knowing that the excess capacity is practically of no benefit to them.
Even if implemented as multiple services, many systems behave in a monolithic manner because of runtime coupling. Tightly coupled services scale horizontally at coarser granularities. So even where horizontal scaling is possible, coarse grained scaling results in underutilised provisioning which cannot be avoided unless systems are decoupled and optimised.
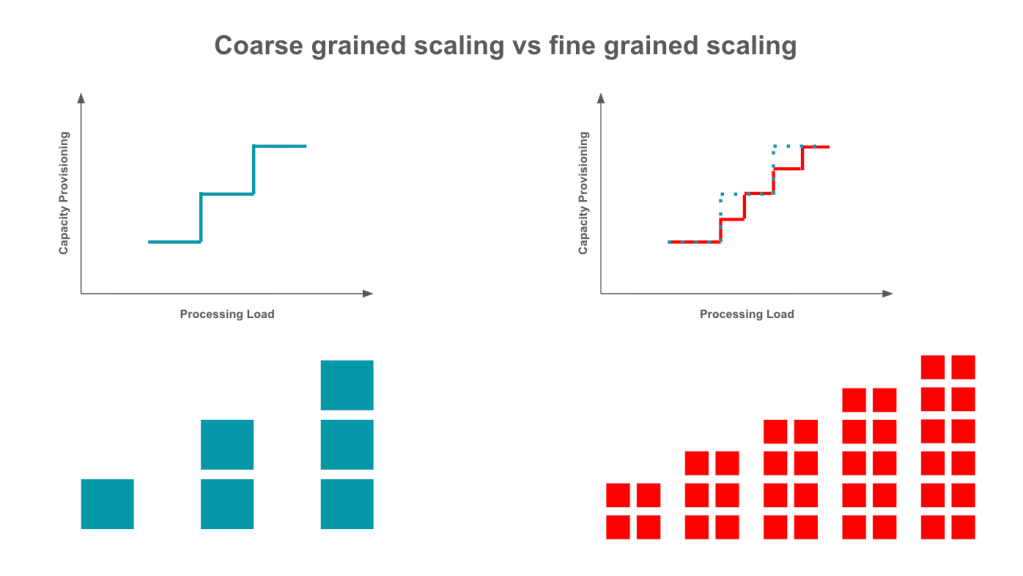
Because of these reasons, forecasting buffers for monolithic services can be substantial for both vertical and horizontal scaling. This then leads to higher overprovisioning and wasted spend.
How to right-size and exploit cloud’s elastic capacity for scaling
Optimisation and waste reduction should be two key focus areas for FinOps specialists.
These start with:
- Building systems to utilise just enough resources for a given load,
- Decommissioning products and services that provide diminishing returns,
- Releasing non-production environments when not in use,
- Right sizing infrastructure to reduce waste,
- Horizontally scaling at finer, service level granularities to accommodate increasing load.
FinOps should coach and advise engineering teams on how to set performance, capacity and utilisation baselines. They should then monitor how these change with load in order to capitalise on optimisation opportunities that help minimise wasted provisioning.
Resource utilisation metrics are leading metrics to cloud costs. These allow FinOps to shift left in systems development. That not only optimises costs but also avoids expensive rework post a cloud bill shock.
Key engineering guiding principles that enable granular scalability involve architecting systems that are:
- Domain aligned,
- Modular,
- Decoupled,
- Composable via APIs and event streams,
- Enable shifting left for early verification of functional and cross functional requirements.
The two key sets of architecture principles that help adopt these guiding principles are MACH and LIFESPAR.
MACH stands for:
- Microservices
- API-first
- Cloud-native
- Headless
LIFESPAR stands for:
- Latency aware
- Instrumented
- Failure aware
- Event driven
- Secure
- Parallelisable
- Resource consumption aware
These may be considered as architecture styles as well as principles. MACH and LIFESPAR are not competing but they are complementary, for example, an architecture may have components that are both API-first and event driven.
FinOps just does not begin and end at engineering. Product management also has a key role to play. Features, products and capabilities that provide diminishing returns should be retired. That leads to releasing compute and storage being used to service these features, products and capabilities. This saves costs.
Successful FinOps, therefore, is a cross functional endeavour requiring strong engineering and product expertise.
Isn’t developer time more expensive than hardware
“Developer time is more expensive than hardware cost“, was a common excuse I heard most times when I tried to motivate engineering managers to optimise their systems for performance, capacity and utilisation.
It was hard to argue against that logic when on-prem, unless we dealt with significant transaction volumes. But things have changed on the public cloud.
This article suggests cloud costs between 3% and 10% of a company’s revenues. 22% of these costs are attributed to AI and ML workloads. For a company with $1 billion annual revenues, this amounts to between $23.4 million and $78 million annually to operate enterprise systems on cloud.
The report does not mention if the firms surveyed were using any cloud discounts. It is inconceivable that they are not. This is not cheap by any stretch even when compared to the cost of developer time.
The key question CIOs and CFOs should be asking themselves is that if they invest in systems optimisation to reduce costs, by when should they see a payback? A simple back-of-the envelope example below can tell us when we can expect an optimisation investment to payback.
- Assuming BAU engineering capacity to be a fourth of cloud costs per year
- Investments in optimisation another fourth of cloud costs per year for 2 years (not taking into consideration any AI acceleration)
- 50% savings expected
- TCO without optimisation = 1.25xy where x is cloud costs, y is the number of years from start
- TCO with optimisation = 3x + (0.75x)(y-2)
- Anticipated payback is at the end of year 3 if cloud cost saving is the only benefit
Of course this is a very simple model. There are several variables, e.g.,
- Cloud prices may change,
- Costs may increase due to increased business activity,
- Anticipated savings may be lower or higher,
- Benefits may include higher revenues due to more elasticity or faster deliveries,
- The amount of effort required is more, or less.
The model can be extended to include all these. The point here is that we can very quickly put our assumptions to test and not just rely on past beliefs that were set in a different context.
Cloud discounts – a cherry on top, not the cake
On-demand provisioning of cloud resources is the most expensive. Cloud providers offer various discounts, the most popular among them being resource reservations or committed usage. Here, consumers commit to a minimum usage for a duration of 1 year or more for discounts of 50% or more as compared to on-demand pricing. In many cases, these discounts can be as high as 70%.
Applying these discounts on a suboptimal estate may reduce costs but not to the levels which could be achieved with performance, capacity and utilisation optimisations. Further, firms should attempt such optimisations before purchasing these discounts. Reversing the order may mean unutilised or underutilised discounts subsequently. In some cases, like with Google’s Committed Usage Discounts (CUDs), commitments are use-it-or-lose-it. Underutilising a discount means that you are still charged the discounted cost for the full commitment even if you reduce your usage.
Also, it is not a good idea to purchase these discounts for the entire forecasted capacity. So, a firm may purchase these discounts for the base load. Purchasing additional discounts should depend on how often and for how long the load spikes from the base load.
Let’s illustrate this with an example.
- If a committed usage commitment provides a 70% discount,
- The base load is 60% of the forecast,
- The remainder 40% are peaks that occur with 20% probability,
- Purchasing a committed usage discount for the average load leads to 79.6% reduction in costs (average load is average of 80 percent of the base load and 20% of 100% of the forecast, resulting in 68% of the forecast)
- If no peaks occur during the contracting period, overprovisioning will only be 8% but at the discounted rate.
- Peaks pushing utilisation above 68% may only occur with a 20% probability and only for the additional 32% utilisation, which may drop the discount to 73.2% (47.6% worst case if that 32% additional utilisation happens throughout the contracting period)
Do we still need forecasting?
To avoid overprovisioning as a consequence of budget forecasting, the perspective on forecasting needs to change. Joe Weinmen, the author of Cloudonomics calls forecasting as fallible. He recommends responding in real time. The goal of forecasting should not be to predict the future but to inform on what needs to be done to take meaningful action in the present.
First, create psychological safety within your teams that with cloud’s just-in-time provisioning and financial accounting, their justified provisioning needs will be met even when they cannot be fully forecasted in the beginning. This may involve getting them to explain their forecasts which will be helpful in using forecasting to track and optimise spending.
Second, forecasted spending needs to be tracked at more granular levels and deviations diagnosed. If cloud spending is increasing because of increased usage, is that increased usage leading to higher revenues, if yes and the margins are being maintained or improved then such spending increase can be justified. Low margins indicate the need for business process and technology optimisations, not just one.
Conclusions
When it comes to managing public cloud environments, we can no longer rely on the comforting, outdated belief that “developer time is always more expensive than hardware.” In a world where cloud spend can consume up to 10% of a company’s revenue, technical efficiency is financial efficiency.
To truly tame raging cloud costs, remember the core sequence:
- Fix the architecture first: Eliminate the rigid, monolithic structures that force you into overprovisioning. Embrace modular, elastic, and decoupled architectures using principles like MACH and LIFESPAR so your infrastructure scales dynamically with actual demand.
- Commit wisely second: Use cloud discounts and committed usage plans as the cherry on top, not the entire cake. Overlay these contracts only after your estate is right-sized and optimised, ensuring you don’t lock yourself into paying for expensive, unused capacity.
- Iterate with dynamic forecasting: Stop using forecasts as a static yearly guessing game that merely predicts waste. Treat forecasting as a real-time diagnostic tool to ensure every dollar increase in cloud spend directly correlates to an increase in business value and margin.
Successful FinOps is not a one-off procurement exercise or an annual budget cleanup. It is a continuous, cross-functional loop that requires engineering, product, and finance to work in lockstep. By optimizing your tech first, leveraging appropriate saving plans second, and using forecasting to continuously refine both, you stop paying for a bloated pint glass you don’t need, and finally start paying only for the value you actually deliver.
